H-AMR: The Next-Gen GRMHD Code
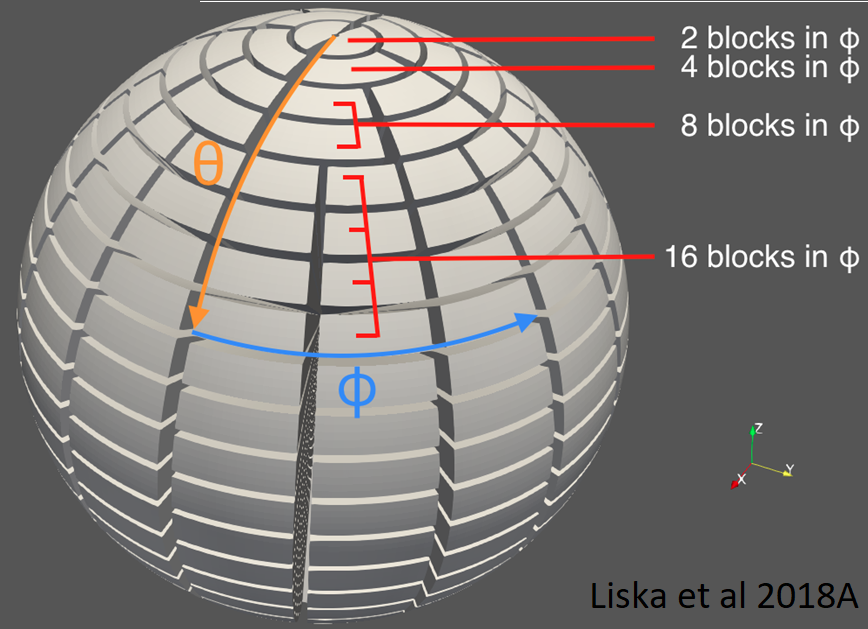
I am the main developer of H-AMR, a massively scalable GPU-accelerated general relativistic magnetohydrodynamics (GRMHD) code. H-AMR features adaptive grids, local adaptive timestepping and novel load balancing routines enabling it to attack challenging problems. H-AMR scales up to large GPU clusters including OLCF's Summit. H-AMR uses a grid-based Godunov scheme to solve the fluid equations, including the induction equation, and incorporates the M1 closure to model radiation. It can also evolve the electron and ion entropies to model two-temperature plasmas. H-AMR is triple level parallelized with CUDA doing most of the computations, with OpenMP handling communication and gridding, and with non-blocking message passing interface (MPI) handling the transfer of boundary cells between nodes.